
前言
本次带来的是一篇2018 CCS Best Paper,主要阐述的是作者实现了一种解释深度学习决策原因的方法:LEMNA。这一方法明显弥补了在安全领域解释方法的稀缺和低保真率的问题。
背景知识
众所周知,深度学习在图片分类上有着比较显著的核心地位,比如: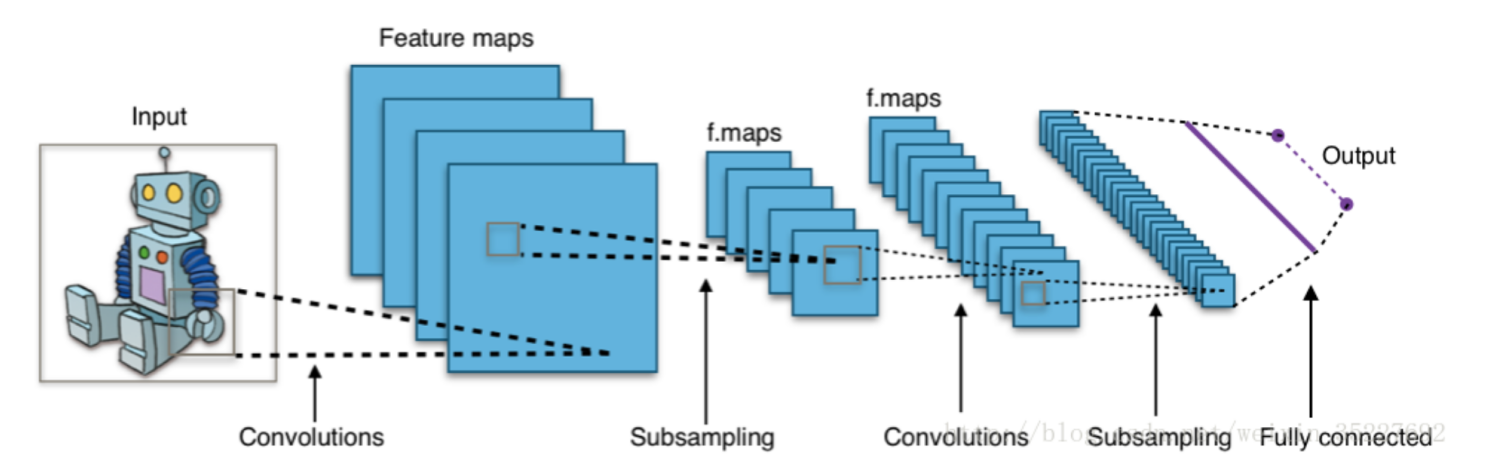
当我们input一张图片给计算机后,计算机可以根据这张图片,输出描述该图像属于某一特定分类的概率的数字(比如:80% 是机器人、15% 是人、5% 是电视机)。
而这一目的的实现,目前一般采用的是CNN(卷积神经网络)。
但是,如果我们需要将相同的目的,转换至安全领域呢?比如恶意软件的分类:我们input一个文件给计算机,计算机是否可以根据这个文件的信息,输出该文件属于某一特定分类的概率的数字呢?比如80%是正常软件、20%是恶意软件。
答案是显然的,但这里我们一般采用的是RNN(循环神经网络)。
那么CNN和RNN有什么区别呢?
我们可以这样简单理解,对于CNN:
- CNN的假设:人类的视觉总是会关注视线内特征最明显的点。
- CNN神经网络是模仿人类处理信息的过程,提取关键信息特点
而对于RNN: - RNN的假设:事物的发展是按照时间序列展开的,即前一刻发生的事物会对未来的事情的发展产生影响
- 处理过程中,每一刻的输出都是带着之前输出值加权之后的结果
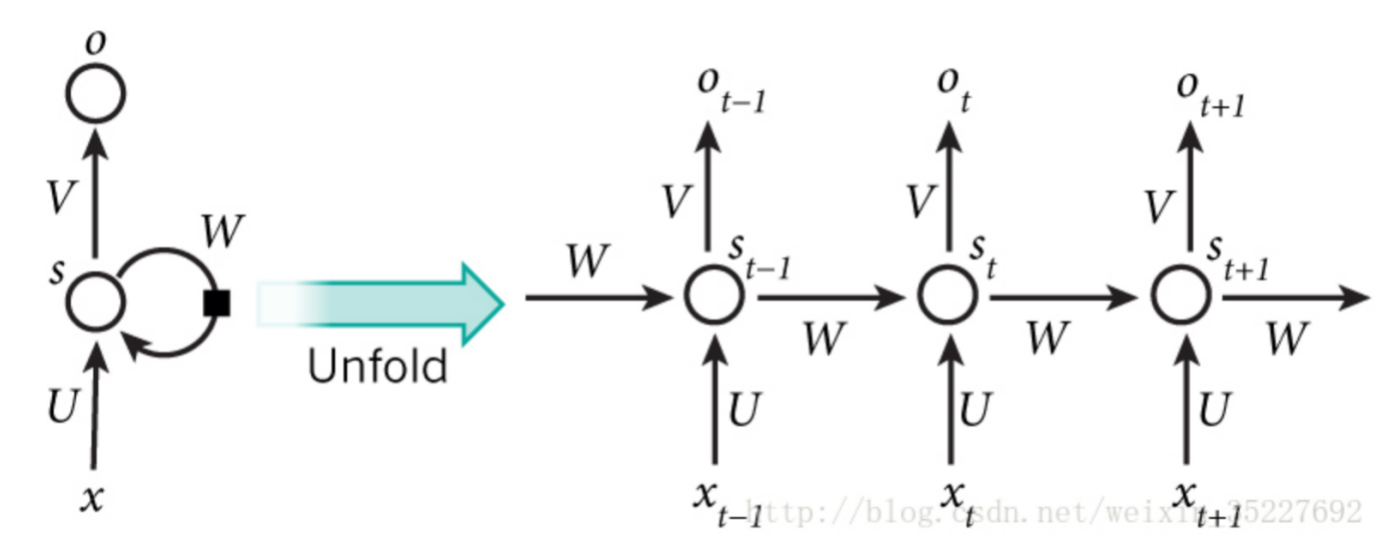
那么为什么对于安全领域,我们偏向于使用RNN也一目了然,很显然程序前后之间是存在关联的,前一段代码势必会对未来执行的代码产生影响,而RNN很好的能将这一点表述出来。
那么决策的解释方法又是什么呢?
举个简单的例子,对于CNN,我们刚才说到,对于我们input的机器人图片,计算机会给出这样的分类概率:80% 是机器人、15% 是人、5% 是电视机。这样的结果和我们所期望的大致一致。但是如果计算机给出的分类概率为:99%是电视机,那么就会出现分类错误。
那么是什么原因导致我们的深度学习分类决策失误呢?这里就需要使用解释方法来进行分析,找到错误,并纠正错误。
举个简单的例子:
比如图片a中,为什么会把图a左边这张图判定为橘子,是因为图a右边高亮的像素点。
又比如图片b中,为什么会把这一段话判定为消极语句,是因为图b中红框高亮的一段话。
只有拥有比较完善的解释方法,我们才可以充分信任分类器做出的决策,否则如果其决策对我们不透明,那么其分类结果也将变得不可信。
而对于解释方法,我们可以大概分为两类,一种为白盒模式,一种为黑盒模式。
对于白盒模式,我们需要提供模型架构、参数、训练数据集,而对于黑盒模式,我们需要不断改变input,观察output,并得出影响决策的关键原因。
那么很明显,白盒模式更加适用于CNN模式,同时大多数工具也是基于白盒模式,开发给CNN使用的。而黑盒模式更加适用于安全领域。
研究问题
本篇paper的研究问题,就在于如何解释深度学习在安全领域上分类决策的原因。深度学习在安全领域也逐渐开始有比较广的应用,但是目前没有一个很好的解释方法可以解释其决策的原因,就会使得我们丢失对分类器的信任。
由于CNN在图片分析上的广泛使用,现有的大多数解释方法全都是供CNN使用。但我们前面提到过,在安全领域,RNN才是更适合的方法。
我们不可能将为CNN设计的解释方法,用于RNN上,这样势必只能获得比较低可信度的结果。
作者首先分析了一下现有的几款解释方法:
不难发现,对于黑盒解释方法,只有LIME有所涉及,但是其对RNN / MLP的支持并不是非常好,同时其采用的是线性回归模型。
那么什么是线性回归模型呢?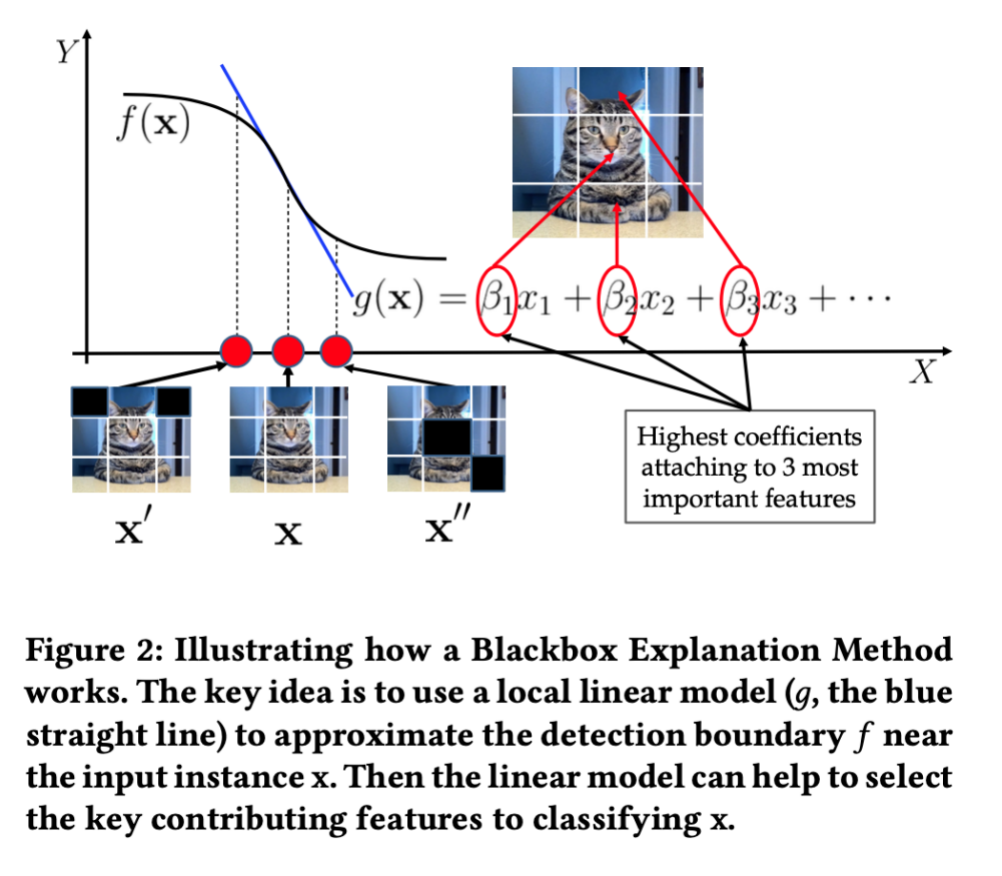
比如这样一只猫的图片,影响该图片被分类为猫的因素肯定有很多,通常可考虑如下的线性关系式: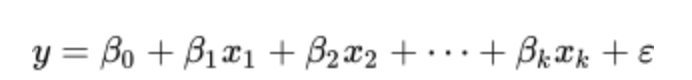
在改变x的时候,我们可以大约探测出图中函数f的边界,这样就可以帮助我们得知,改变哪些x的时候,会对分类产生关键的影响。而其对应的特征,就是影响决策的关键特征。
但是作者发现,这样的方式,在对于复杂模型的时候,并不适用,存在比较大的误差: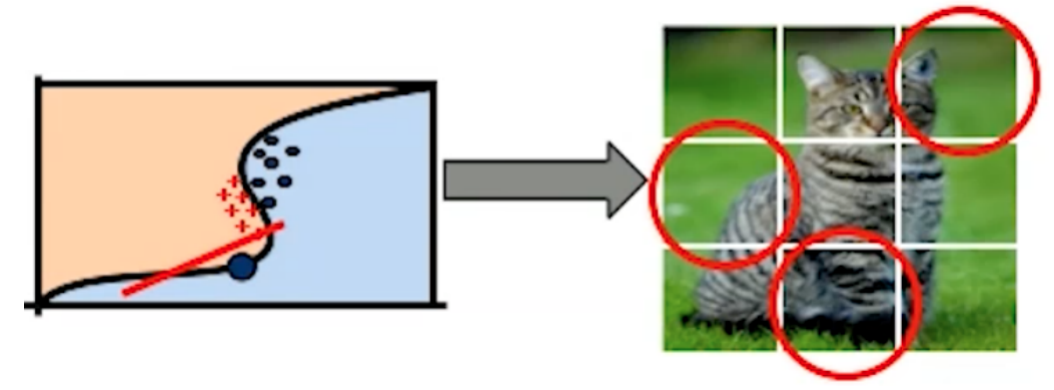
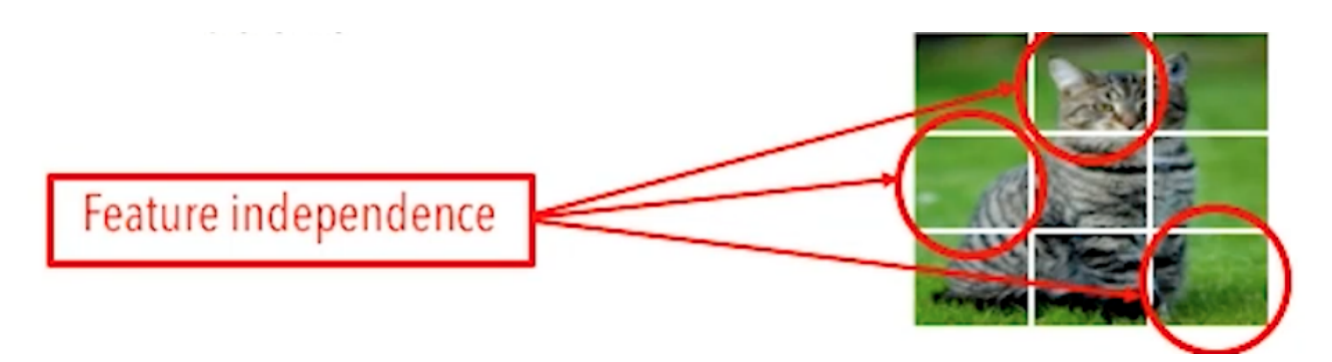
我们在用该方式处理复杂问题时,它会将每一个特征视为独立的,但我们知道这些特征势必是有相互关联性的,比如一只猫不可能只有耳朵,没有脸。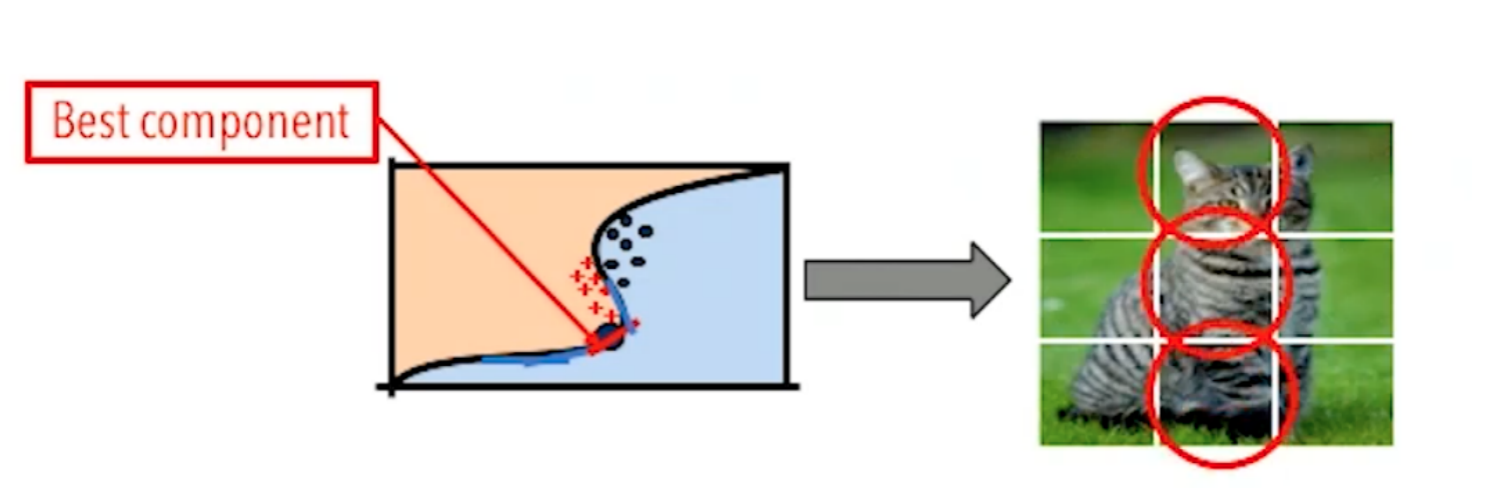
其最佳的方法不应该选用线性回归模型,还应该使用混合回归模型: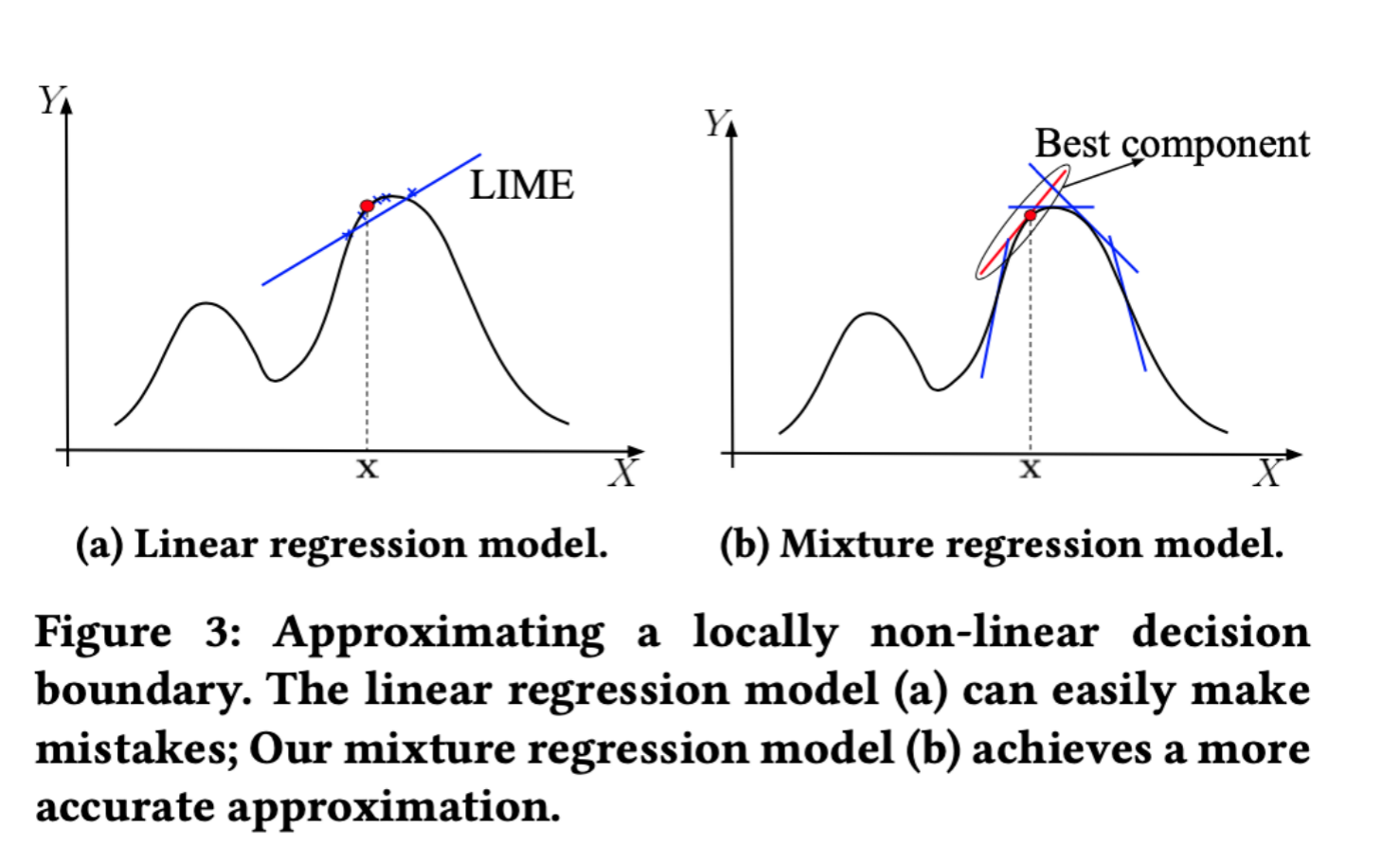
简而言之,就是由多个线性回归模型组成的模型,这样才能更好的探测出函数f的边界。
所以为了解决线性回归模型的弊端问题,作者尝试引入了混合回归模型。而为了解决特征之间的相互依赖关系,作者使用了fused lasso(惩罚最小一乘回归)。如此一来,将混合回归模型和惩罚最小一乘回归二者结合,即可比较完美的解决LIME的弊端问题。
现实评估
作者使用了混合回归模型和惩罚最小一乘回归二者结合的解释方法,主要分析了如下两种情况:
1、解释逆向工程中查找函数开头的决策原因:即为什么把这个位置标记为函数开头。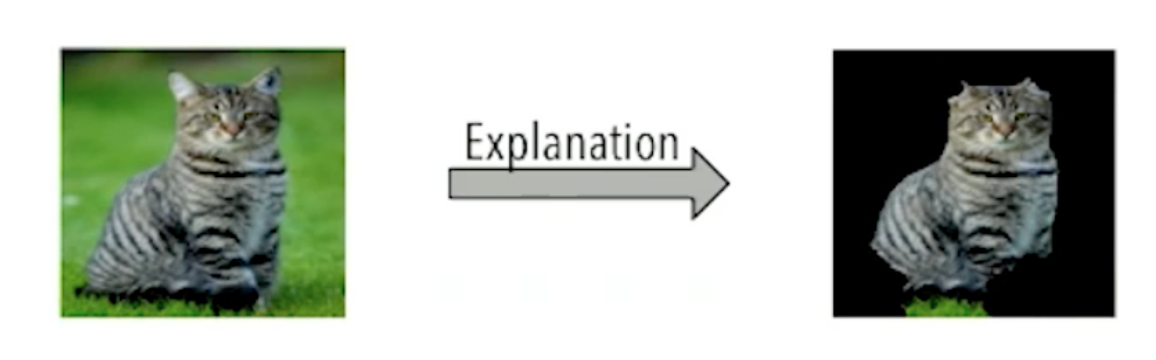
例如在图片中,我们将这种图判定为猫的主要原因,是因为右边高亮的像素点,这是解释器需要给出的原因。
而在二进制文件分析中也一样: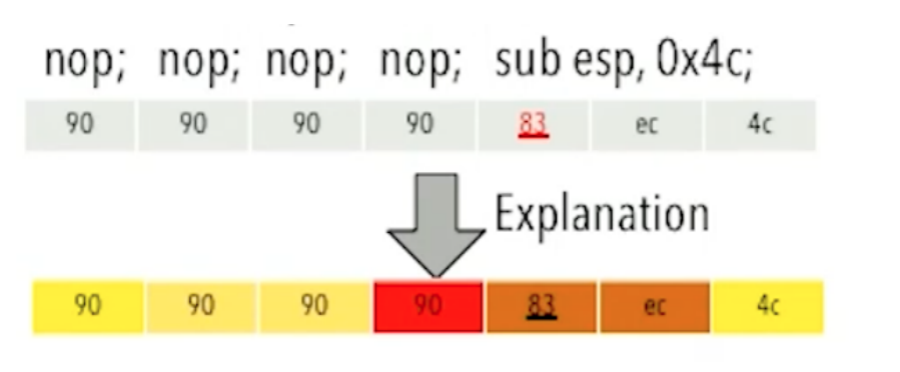
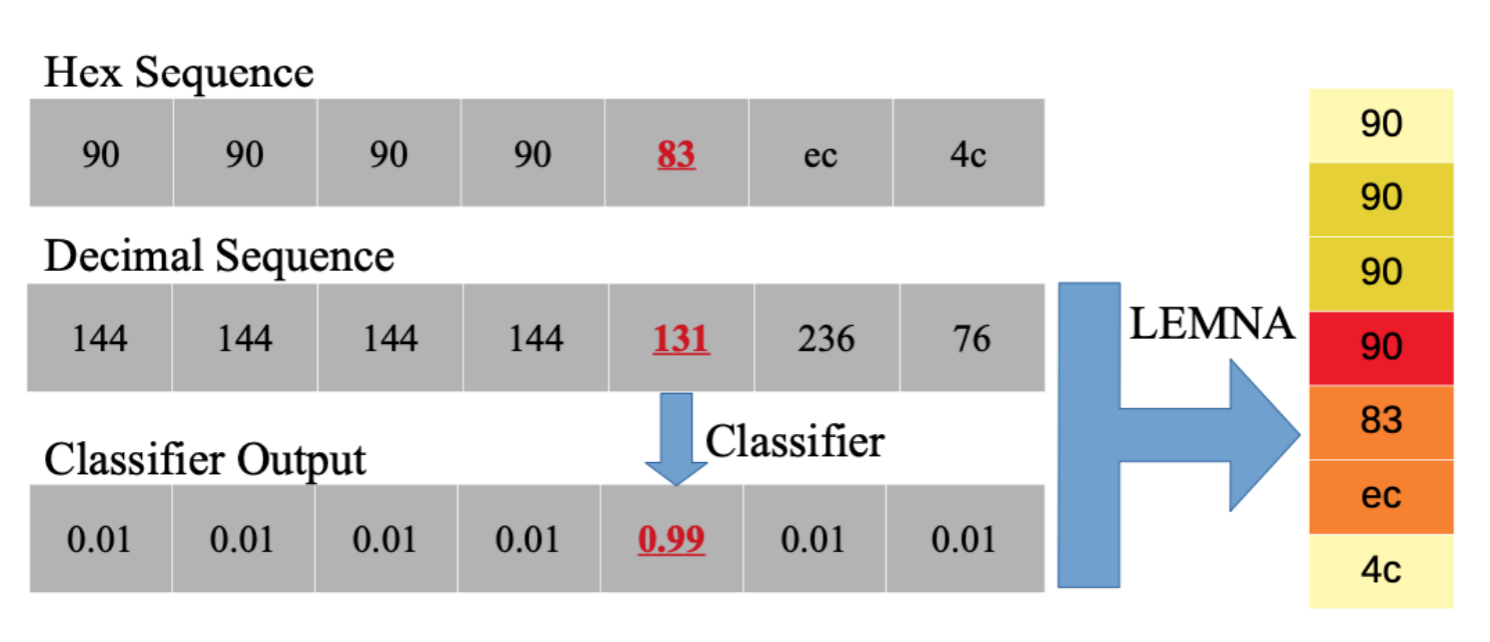
我们为什么把83认定为函数开头位置,是因为其前面90的位置。这也是解释器需要给出的原因。
2、解释PDF恶意文件分类的决策原因:即为什么把这个PDF判定为正常文件/恶意文件。
作者设置了如下数据集:
对于逆向工程,作者使用了2200个binary文件,在x86下利用gcc的4种不同优化模式(O0, O1, O2, O3)进行编译。
然后将数据集中70%用于训练,30%用户测试。
对于PDF文件,作者使用了4999个恶意文件和5000个正常文件,并从中提取了135个特征点。并将其也按照7:3分为训练集和测试集。
在结果上,我们可以发现拥有相当高的准确度: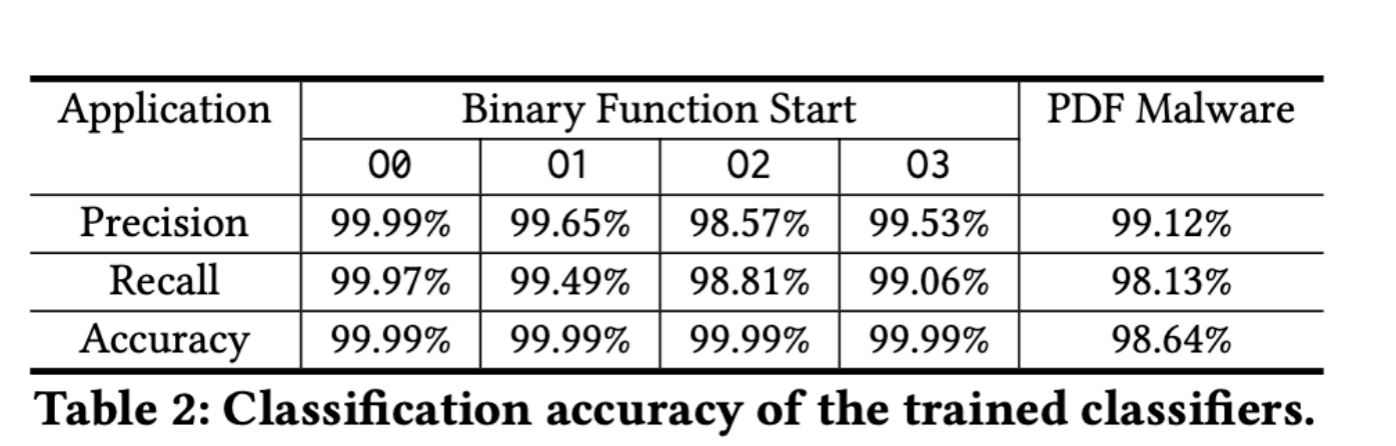
除此之外,作者还对自己的LEMNA的解释保真度进行了评估,即决策的重要原因找的对不对。
为此作者设计了两大组实验:
第一组实验,作者使用了公式进行评估,即均方根误差(Root Mean Square Error):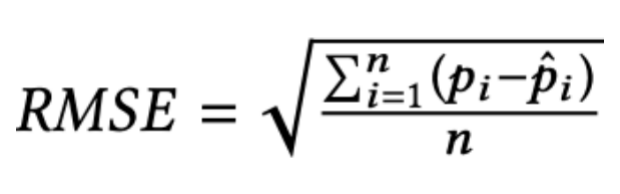
pi表示目标分类器分类为target的概率、pi-hat表示使用混合回归模型分类为target的概率。
那么RMSE越小,说明决策边界找的和目标分类器越一致。
作者使用LIME作为参照体: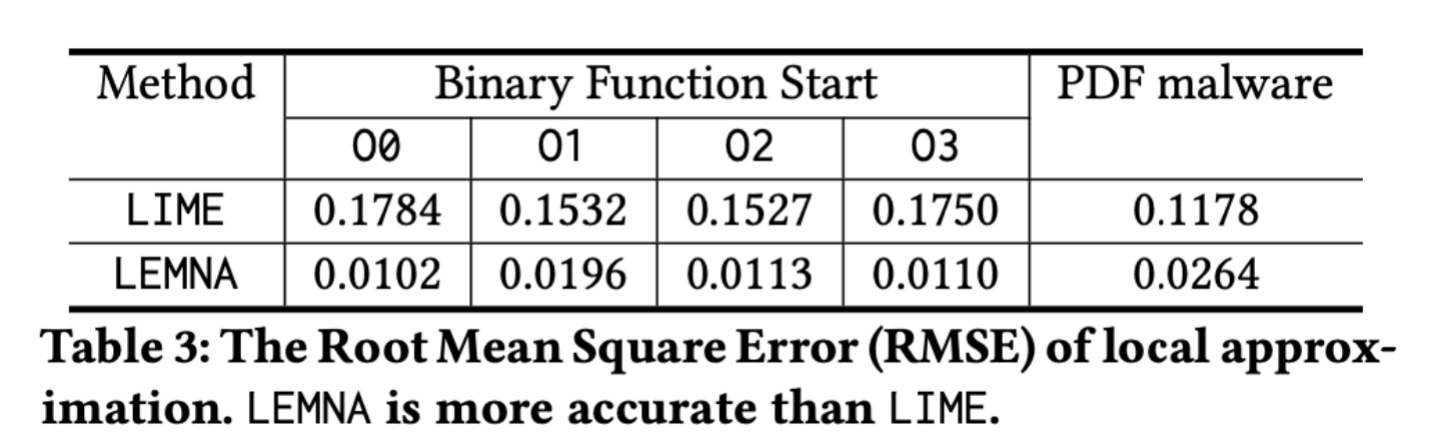
我们可以发现,作者提出的LEMNA的边界寻找准确度比前人工作LIME在逆向工程上高出了将近10倍,在PDF恶意文件分类上高出了5倍。这也充分证实了混合线性模型对比线性模式的优势。
第二组实验,作者使用了如下3个小实验:
比如用图片举例,我们input进去一张图片(a),解释器告诉我们将这张图片分类为毛衣,而不是鞋子的关键原因:图片(b)(关键像素已由红点高亮)
那么我们的3组实验分别为:
图片c:我们将解释器得出的关键像素去除,再丢入分类器,如果分类器将其判定为非毛衣的可能性与我们去除关键像素的个数成反比,那么说明解释器解释的越正确。
图片d:我们仅留下关键像素,同时加入一双鞋子做干扰,如果分类器将其判定为毛衣的可能性与我们加入关键像素的个数呈正比,那么说明解释器解释的越正确。
图片e:在图片d的基础上去除干扰,在我们加入关键像素点越少的情况下,如果分类器已经可以很高概率将其判定为毛衣,那么我们的解释器解释的越正确。
结果也证实了,作者的工具拥有最高的效率(图中红线为作者工具):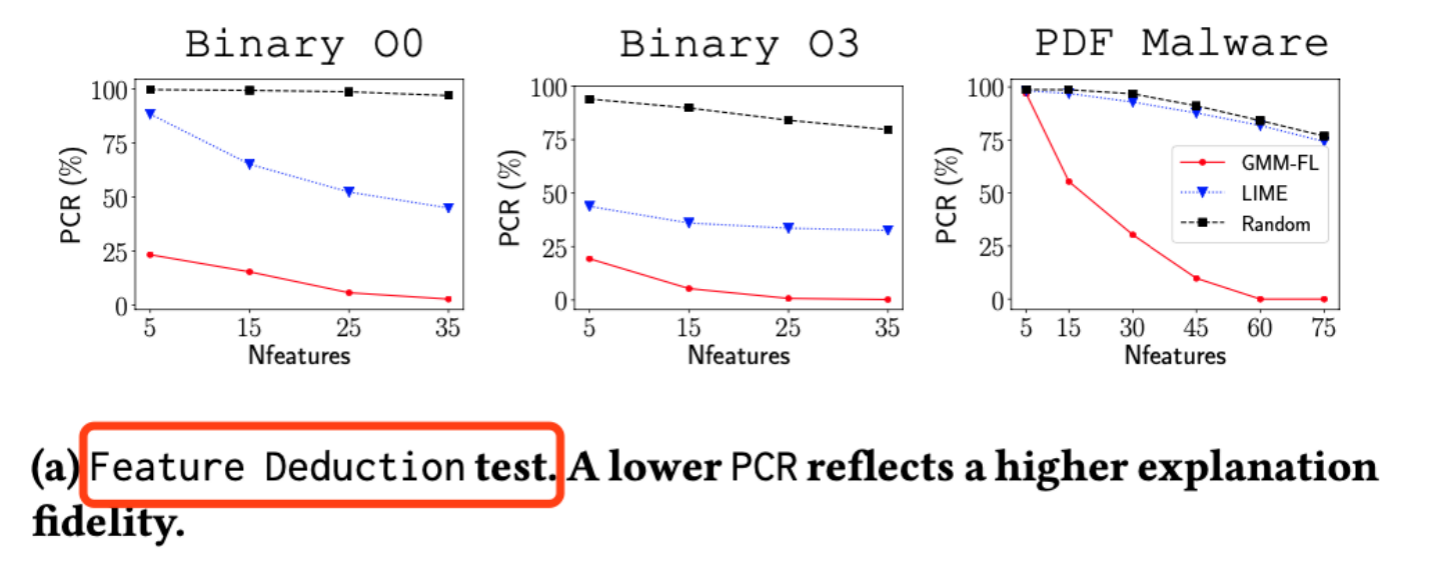
对于图片c模式的测试下,作者在仅去除5个关键点后,分类器的分类成功率就已经在一个非常低的水准了,而其他前人的方法还在一个比较高的成功率,这充分说明了,作者的解释方法找到的关键因素才为保真度非常高的关键因素。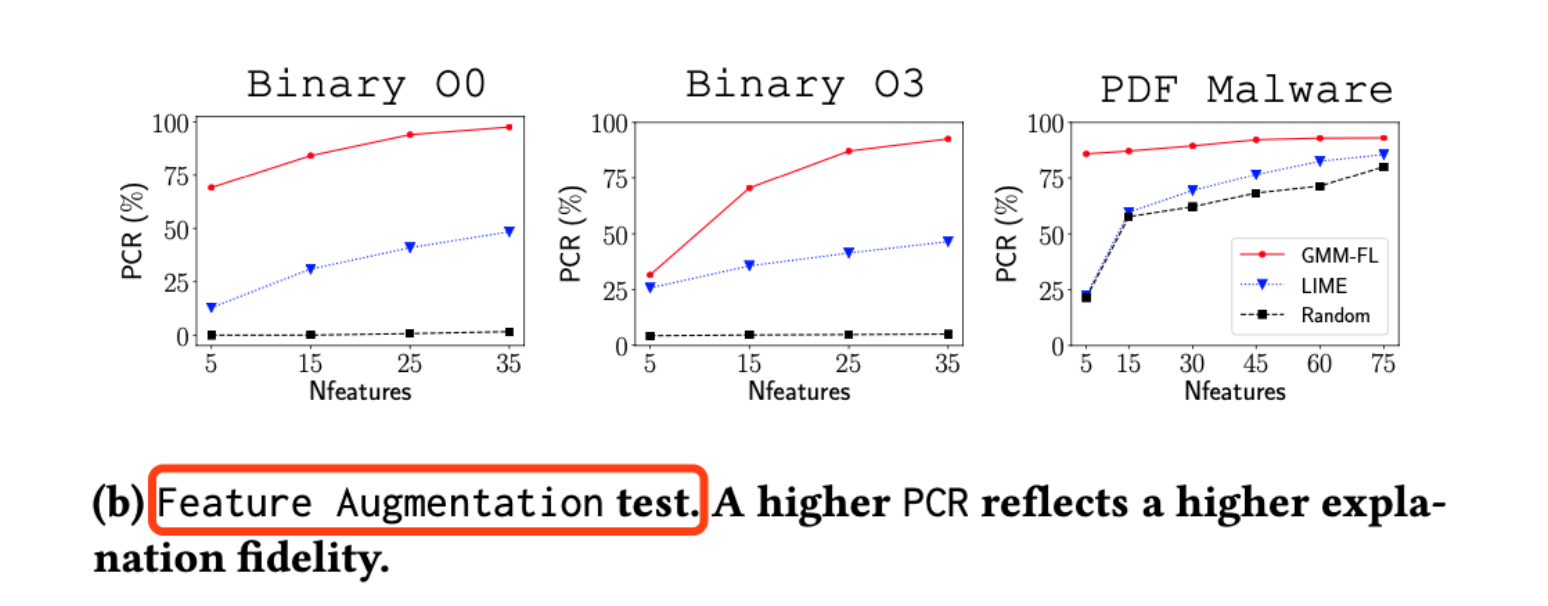
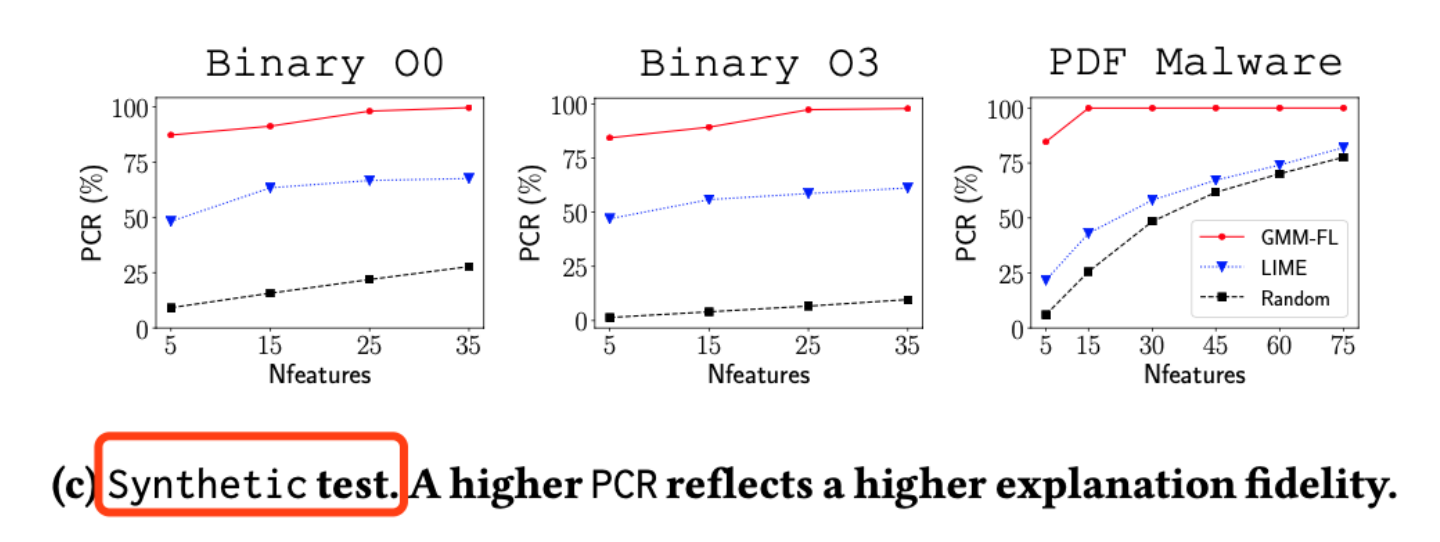
同理,对于图片d和图片e模式下的测试,作者在仅用5个关键特征的情况下,就已经让分类器达到了比较高的准确率,这也同样说明了作者的工具解释出的关键特征,具有更高的保真度。
总结
总得来说,本篇paper在安全领域的深度学习决策解释上填补了空缺,同时其解释的关键原因具有非常高的可信度,效果也是远好于前人设计的解释方法。

