
前记
快考试了,写一写要上机考试的题目……很不优雅,请大佬指点,算法很渣
第3章——动态规划
矩阵连乘
题目描述
动态规划方程: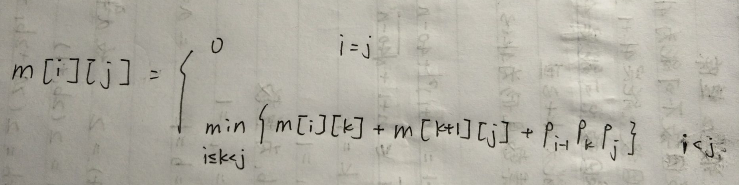
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
using namespace std;
static int m[301][301] = { 0 };
int main()
{
int n;
cin >> n;
int *p = new int[n + 1];
for (int i = 0; i < n+1; i++)
{
cin >> p[i];
}
for (int len = 2; len <= n; len++)
{
for (int i = 1; i <= n - len + 1; i++)
{
int j = i + len - 1;
m[i][j] = inf;
for (int k = i; k < j; k++)
{
m[i][j] = min(m[i][j], m[i][k] + m[k + 1][j] + p[i - 1] * p[k] * p[j]);
}
}
}
cout << m[1][n];
}
然后下面是附带加括号方法的写法(只是多了s[i][j]数组和回溯)
输入:1
26
30 35 15 5 10 20 25
输出1
2
3
4
5
6Multiply A2,2and A3,3
Multiply A1,1and A2,3
Multiply A4,4and A5,5
Multiply A4,5and A6,6
Multiply A1,3and A4,6
最少计算次数为: 15125
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
using namespace std;
int m[1005][1005] = {0};
int s[1005][1005] = { 0 };
void Traceback(int i, int j)
{
if (i==j)
{
return;
}
Traceback(i, s[i][j]);
Traceback(s[i][j]+1,j);
cout << "Multiply A" << i << "," << s[i][j];
cout << "and A" << s[i][j] + 1 << "," << j << endl;
}
int main()
{
int n; //矩阵的个数
cin >> n;
int *p = new int[n + 1];
for (int i = 0; i < n+1; i++)
{
cin >> p[i];
}
for (int len = 2; len <= n; len++)
{
for (int i = 1; i <= n - len + 1; i++)
{
int j = i + len - 1;
m[i][j] = inf;
for (int k = i; k < j; k++)
{
int t = m[i][k] + m[k + 1][j] + p[i - 1] * p[k] * p[j];
if (m[i][j]>t)
{
m[i][j] = t;
s[i][j] = k;
}
}
}
}
Traceback(1, n);
cout << "最少计算次数为: " << m[1][n] << endl;
system("pause");
}
最长公共子序列
题目描述1
2
3
4
5
6
7
8
9
10
11
12
13
14一个字符串A的子串被定义成从A中顺次选出若干个字符构成的串。如A=“cdaad" ,顺次选1,3,5个字符就构成子串" cad" ,现给定两个字符串,求它们的最长共公子串。
输入格式:第一行两个字符串用空格分开。
输出格式:最长子串的长度。
两个串的长度均小于2000
样例输入
abccd aecd
样例输出
3
动态规划方程: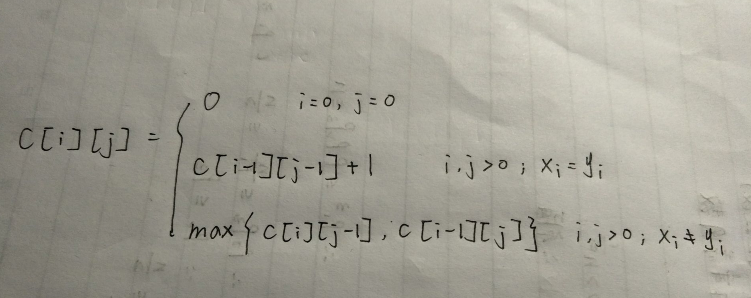
代码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
using namespace std;
static int c[2000][2000] = { 0 };
int main()
{
string a, b;
cin >> a >> b;
for (int i = 1; i <= a.length(); i++)
{
for (int j = 1; j <= b.length(); j++)
{
if (a[i - 1] == b[j - 1])
{
c[i][j] = c[i - 1][j - 1] + 1;
}
else
{
c[i][j] = max(c[i][j - 1], c[i - 1][j]);
}
}
}
cout << c[a.length()][b.length()] << endl;
}
下面给出最大公共子序列的算法,而非最大公共子序列长度
输入:1
abccd aecd
输出:1
2acd
最长公共子序列的长度为: 3
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
using namespace std;
int c[1005][1005];
int s[1005][1005];
void LCS(int i, int j,string a)
{
if (i == 0 || j == 0)
{
return;
}
if (s[i][j]==1)
{
LCS(i - 1, j - 1,a);
cout << a[i-1]; //注:书上是a[i],因为用的是char数组,从char[1]开始的,而这里我用的string
}
else if (s[i][j] == 2)
{
LCS(i - 1, j,a);
}
else
{
LCS(i, j - 1,a);
}
}
int main()
{
string a, b;
cin >> a >> b;
for (int i = 1; i <= a.length(); i++)
{
for (int j = 1; j <= b.length(); j++)
{
if (a[i - 1] == b[j - 1])
{
c[i][j] = c[i - 1][j - 1] + 1;
s[i][j] = 1;
}
else
{
if (c[i-1][j]>= c[i][j - 1])
{
c[i][j] = c[i-1][j];
s[i][j] = 2;
}
else
{
c[i][j] = c[i][j-1];
s[i][j] = 3;
}
}
}
}
LCS(a.length(), b.length(),a);
cout << endl;
cout << "最长公共子序列的长度为: " << c[a.length()][b.length()] << endl;
system("pause");
}
最大子段和
题目描述1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25给出一个整数数组a(正负数都有),如何找出一个连续子数组(可以一个都不取,那么结果为0),使得其中的和最大?
例如:-2,11,-4,13,-5,-2,和最大的子段为:11,-4,13。和为20。
输入
第1行:整数序列的长度N(2 <= N <= 50000)
第2 - N + 1行:N个整数(-10^9 <= A[i] <= 10^9)
输出
输出最大子段和。
输入示例
6
-2
11
-4
13
-5
-2
输出示例
20
代码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
using namespace std;
int MaxSum(int n, int a[])
{
int sum = -inf;
int b = 0;
for (int i = 0; i < n; i++)
{
if (b > 0)
{
b += a[i];
}
else
{
b = a[i];
}
sum = max(b, sum);
}
return sum;
}
int main()
{
int n;
cin >> n;
int* a = new int[n];
for (int i = 0; i < n; i++)
{
cin >> a[i];
}
cout << MaxSum(n, a) << endl;
system("pause");
}
沙子的质量
题目描述1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21设有N堆沙子排成一排,其编号为1,2,3,…,N(N< =300)。每堆沙子有一定的数量,可以用一个整数来描述,现在要将这N堆沙子合并成为一堆,每次只能合并相邻的两堆,合并的代价为这两堆沙子的数量之和,合并后与这两堆沙子相邻的沙子将和新堆相邻,合并时由于选择的顺序不同,合并的总代价也不相同,如有4堆沙子分别为 1 3 5 2 我们可以先合并1、2堆,代价为4,得到4 5 2 又合并 1,2堆,代价为9,得到9 2 ,再合并得到11,总代价为4+9+11=24,如果第二步是先合并2,3堆,则代价为7,得到4 7,最后一次合并代价为11,总代价为4+7+11=22;
问题是:找出一种合理的方法,使总的代价最小。输出最小代价。
输入格式:
第一行一个数N表示沙子的堆数N。 第二行N个数,表示每堆沙子的质量。 < =1000
输出格式:
合并的最小代价
样例输入
4
1 3 5 2
样例输出
22
动态规划方程: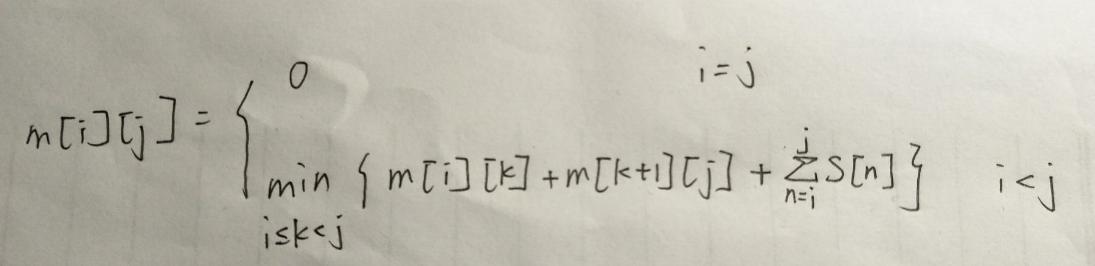
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
using namespace std;
static int sum[1001][1001] = { 0 };
static int m[1001][1001] = { 0 };
int main()
{
int N;
cin >> N;
int *sands = new int[N + 1];
for (int i = 1; i <= N; i++)
{
cin >> sands[i];
sum[i][i] = sands[i];
}
for (int i = 1; i <= N; i++)
{
for (int j = i+1; j <= N; j++)
{
sum[i][j] = sum[i][j - 1] + sands[j];
}
}
for (int len = 2; len <= N; len++) //将问题化为长度为len的子问题,len的长度从 2~N遍历 1的时候都为0
{
for (int i = 1; i <= N - len + 1; i++) //遍历长度为len的子问题
{
int j = i + len - 1; //长度为len的子问题,左端是i,右端是j
m[i][j] = inf;
for (int k = i; k < j; k++)
{
m[i][j] = min(m[i][j], m[i][k] + m[k + 1][j] + sum[i][j]);
}
}
}
cout << m[1][N] << endl;
}
这里同样给出沙子质量划分的方法:
输入:1
24
1 3 5 2
输出:1
2
3
4Sands A1,1And A2,2
Sands A3,3And A4,4
Sands A1,2And A3,4
22
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
using namespace std;
int m[1005][1005]; //记录结果
int sum[1005][1005]; //预处理
int sands[1005]; //沙子的质量
int s[1005][1005]; //回溯记录
void LCS(int i, int j)
{
if (i==j)
{
return;
}
LCS(i, s[i][j]);
LCS(s[i][j] + 1, j);
cout << "Sands A" << i << "," << s[i][j];
cout << "And A" << s[i][j] + 1 << "," << j << endl;
}
int main()
{
int n;
cin >> n;
for (int i = 1; i <= n; i++)
{
cin >> sands[i];
sum[i][i] = sands[i];
}
for (int i = 1; i <= n; i++)
{
for (int j = i + 1; j <= n; j++)
{
sum[i][j] = sum[i][j - 1] + sands[j];
}
}
for (int len = 2; len <= n; len++)
{
for (int i = 1; i <= n - len + 1; i++)
{
int j = i + len - 1;
m[i][j] = inf;
for (int k = i; k < j; k++)
{
int t = m[i][k] + m[k + 1][j] + sum[i][j];
if (m[i][j]>t)
{
m[i][j] = t;
s[i][j] = k;
}
}
}
}
LCS(1, n);
cout << m[1][n] << endl;
system("pause");
}
0-1背包问题
草药的价值
题目描述1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17辰辰是个天资聪颖的孩子,他的梦想是成为世界上最伟大的医师。为此,他想拜附近最有威望的医师为师。医师为了判断他的资质,给他出了一个难题。医师把他带到一个到处都是草药的山洞里对他说:“孩子,这个山洞里有一些不同的草药,采每一株都需要一些时间,每一株也有它自身的价值。我会给你一段时间,在这段时间里,你可以采到一些草药。如果你是一个聪明的孩子,你应该可以让采到的草药的总价值最大。” 如果你是辰辰,你能完成这个任务吗?
输入文件medic.in的第一行有两个整数T(1 < = T < = 1000)和M(1 < = M < = 100),用一个空格隔开,T代表总共能够用来采药的时间,M代表山洞里的草药的数目。接下来的M行每行包括两个在1到100之间(包括1和100)的整数,分别表示采摘某株草药的时间和这株草药的价值。
输出文件medic.out包括一行,这一行只包含一个整数,表示在规定的时间内,可以采到的草药的最大总价值。
对于30%的数据,M < = 10;对于全部的数据,M < = 100。
样例输入
70 3
71 100
69 1
1 2
样例输出
3
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
using namespace std;
static int cost[1005][1005];
typedef struct med
{
int t;//采草药的时间
int v;//草药的价值
}med;
int main()
{
int n;//草药的个数
int m;//背包的容量
cin >> m >> n;
med *arr = new med[n + 1];
for (int i = 1; i <= n; i++)
{
cin >> arr[i].t >> arr[i].v;
}
memset(cost, 0, sizeof(cost)); //将记录数组置0
for (int i = n; i >= 1; i--) //行数,个数的遍历,从最下面一行开始遍历
{
for (int j = 0; j <= m; j++) //列数,从小到大遍历
{
if (j >= arr[i].t) //如果可以放的进来,就在放和不放之间挑一个最大的
{
cost[i][j] = max(cost[i + 1][j], cost[i + 1][j - arr[i].t] + arr[i].v);
}
else //如果放不进来,就不放了
{
cost[i][j] = cost[i + 1][j];
}
}
}
cout << cost[1][m] << endl; //右上角即答案
}
然后是取舍方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
using namespace std;
int m[1005][1005];
int x[1005];
typedef struct node
{
int v;
int w;
}node;
int main()
{
int c, n; //c为重量上限,n为物品个数
cin >> c >> n;
node *arr = new node[n+1];
for (int i = 1; i <= n; i++)
{
cin >> arr[i].w >> arr[i].v;
}
memset(m, 0, sizeof(m));
for (int i = n; i>=1; i--)
{
for (int j = 0; j <= c; j++)
{
if (arr[i].w<=j)
{
m[i][j] = max(m[i+1][j], m[i+1][j - arr[i].w] + arr[i].v);
}
else
{
m[i][j] = m[i + 1][j];
}
}
}
cout << "最大装载重量为: " << m[1][c] << endl;
for (int i = 1; i < n; i++)
{
if (m[i][c] == m[i + 1][c])
{
x[i] = 0;
}
else
{
x[i] = 1;
c -= arr[i].w;
}
}
x[n] = (m[n][c]) ? 1 : 0;
for (int i = 1; i <= n; i++)
{
cout << x[i] << " ";
}
}
节食的限制
题目描述:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23Bessie像她的诸多姊妹一样,因為从Farmer John的草地吃了太多美味的草而长出了太多的赘肉。所以FJ将她置於一个及其严格的节食计划之中。她每天不能吃多过H (5 < = H < = 45,000)公斤的乾草。 Bessie只能吃一整綑乾草;当她开始吃一綑乾草的之后就再也停不下来了。她有一个完整的N (1 < = N < = 500)綑可以给她当作晚餐的乾草的清单。她自然想要尽量吃到更多的乾草。很自然地,每綑乾草只能被吃一次(即使在列表中相同的重量可能出现2次,但是这表示的是两綑乾草,其中每綑乾草最多只能被吃掉一次)。 给定一个列表表示每綑乾草的重量S_i (1 < = S_i < = H), 求Bessie不超过节食的限制的前提下可以吃掉多少乾草(注意一旦她开始吃一綑乾草就会把那一綑乾草全部吃完)。
输入格式:
* 第一行: 两个由空格隔开的整数: H 和 N * 第2到第N+1行: 第i+1行是一个单独的整数,表示第i綑乾草的重量S_i。
输出格式:
* 第一行: 一个单独的整数表示Bessie在限制范围内最多可以吃多少公斤的乾草。
样例输入
56 4
15
19
20
21
样例输出
56
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
using namespace std;
int main()
{
int c; //最多吃的干草量
int n; //有多少捆干草
cin >> c >> n;
int *wei = new int[n + 1];
int m[50000];
for (int i = 1; i <= n; i++)
{
cin >> wei[i];
}
memset(m, 0, sizeof(m));
for (int i = 1; i <= n; i++)
{
for (int j = c; j >= wei[i]; j--) //j从大到小倒着遍历,如果大于重量,则说明可以放入,反之,则放弃这个物品,从下一个物品开始
{
m[j] = max(m[j], m[j - wei[i]] + wei[i]);
}
}
cout << m[c] << endl;
}
然后是取舍的方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
using namespace std;
int f[50000];
int s[50000];
int main()
{
int c, n; //c为重量限制,n为个数
cin >> c >> n;
int *arr = new int[n + 1];
for (int i = 1; i <= n; i++)
{
cin >> arr[i];
}
memset(f, 0, sizeof(f));
memset(s, 0, sizeof(s));
for (int i = 1; i <= n; i++)
{
for (int j = c; j >= arr[i]; j--) //j从大到小倒着遍历,如果大于重量,则说明可以放入,反之,则放弃这个物品,从下一个物品开始
{
if (f[j]<f[j - arr[i]] + arr[i])
{
f[j] = f[j - arr[i]] + arr[i];
}
}
}
int k = n;
while (c >= 0 && k>0)
{
if (f[c] == f[c - arr[k]] + arr[k])
{
s[k] = 1;
c -= arr[k];
}
else
{
s[k] = 0;
}
k--;
}
for (int i = 1; i <= n; i++)
{
cout << s[i] << " ";
}
}
第4章——贪心算法
活动安排
贪婪策略:
按结束时间进行排序,优先完成结束时间早的任务。
书上原样算法
题目描述:1
理论上,Nova君是个大闲人,但每天还是有一大堆事要干,大作业啦,创新杯啦,游戏啦,出题坑人啦,balabala......然而精力有限,Nova君同一时间只能做一件事,并不能一心二用。假设现在有N项工作等待Nova君完成,分别在 Si 时刻开始,在 Ti 时刻结束,对于每项工作可以选择做或者不做,但不可以同时选择时间重叠的工作(即使是开始的瞬间和结束的瞬间重叠也是不允许的)。Nova君自然希望尽量多做一些事情,那么最多能做几件事呢?
输入1
2
3多组测试数据(数据组数不超过10),对于每组数据,第一行输入一个正整数N,代表可选的工作数量,接下来输入N行,每行两个正整数,代表第 i 个工作的开始时间 si 和结束时间 ti 。
1<=N<=100000 | 1<=si<=ti<=10^9
输出1
对于每组数据,输出一行,为可完成的工作的最大数量。
样例1
2
3
4
5
65
1 3
2 5
4 7
6 9
8 10
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
using namespace std;
typedef struct work
{
int begin;
int end;
}work;
bool cmp(work a, work b)
{
return a.end < b.end;
}
int main()
{
int num;
cin >> num;
work*arr = new work[num];
for (int i = 0; i < num; i++)
{
cin >> arr[i].begin >> arr[i].end;
}
sort(arr, arr + num, cmp);
int j = 0;
int fin = 1;
for (int i = 1; i < num; i++)
{
if (arr[i].begin >= arr[j].end)
{
fin++;
j = i;
}
}
cout << fin << endl;
system("pause");
}
法师康的工人
题目描述:1
2
3
4
5
6
7
8
9三个法师康的工人每天早上6点到工厂开始到三条产品生产线上组装桔子手机。第一个工人在200时刻开始(从6点开始计时,以秒作为单位)在生产线上开始生产,一直到1000时刻。第二个工人,在700时刻开始,在1100时刻结束。第三个工人从1500时刻工作到2100时刻。期间最长至少有一个工人在生产线上工作的连续时间为900秒(从200时刻到1100时刻),而最长的无人生产的连续时间(从生产开始到生产结束)为400时刻(1100时刻到1500时刻)。
你的任务是用一个程序衡量N个工人在N条产品线上的工作时间列表(1≤N≤5000,以秒为单位)。
·最长的至少有一个工人在工作的时间段
·最长的无人工作的时间段(从有人工作开始计)
输入第1行为一个整数N,第2-N+1行每行包括两个均小于1000000的非负整数数据,表示其中一个工人的生产开始时间与结束时间。输出为一行,用空格分隔开两个我们所求的数。
样例输入1
2
3
43
200 1000
700 1100
1500 2100
样例输出1
900 400
代码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
using namespace std;
typedef struct work
{
int begin;
int end;
}work;
bool cmp(work a, work b)
{
return a.begin < b.begin;
}
int main()
{
int num;
cin >> num;
work*arr = new work[num];
for (int i = 0; i < num; i++)
{
cin >> arr[i].begin >> arr[i].end;
}
sort(arr, arr + num, cmp);
int peo_y = 0;
int peo_n = 0;
int left = arr[0].begin;
int right = arr[0].end;
for (int i = 1; i < num; i++)
{
if (arr[i].begin<=right)
{
right = max(right,arr[i].end);
}
else
{
peo_n = max(peo_n, (arr[i].begin - right));
left = arr[i].begin;
right = arr[i].end;
}
peo_y = max(peo_y, (right - left));
}
peo_y = max(peo_y, (right - left));
cout << peo_y << " " << peo_n << endl;
system("pause");
}
区间包含
题目描述:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34已知 n 个左闭右开区间 [ a , b) ,对其进行 m 次询问,求区间 [ l , r ] 最多可以包含 n 个区间中的多少个区间,并且被包含的所有区间都不相交。
输入格式
输入包含多组测试数据,对于每组测试数据:
第一行包含两个整数 n m ( 1 ≤ n , m ≤ 100000 ) 。
接下来 n 行每行包含两个整数 a b ( 0 ≤ a < b ≤ 10^9) 。
接下来 m 行每行包含两个整数 l r ( 0 ≤ l < r ≤ 10^9) 。
输出格式
对于每组测试数据,输出 m 行,每行包含一个整数。
样例输入
4 3
1 3
2 4
1 4
1 2
1 2
1 3
1 4
样例输出
1
1
2
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
using namespace std;
typedef struct node
{
int l;
int r;
}node;
bool cmp(node a, node b)
{
return a.r < b.r;
}
int main()
{
std::ios::sync_with_stdio(false);
int n, m;
while (cin >> n >> m)
{
node *nnum = new node[n];
node *mnum = new node[m];
for (int i = 0; i < n; i++)
{
cin >> nnum[i].l >> nnum[i].r;
}
for (int i = 0; i < m; i++)
{
cin >> mnum[i].l >> mnum[i].r;
}
sort(nnum, nnum + n, cmp);
for (int i = 0; i < m; i++)
{
int res = 0;
int k = mnum[i].l; //K初始的时候等于m数组的左边界
for (int j = 0; j < n; j++)
{
if ((nnum[j].l >= k))
{
if (nnum[j].r <= mnum[i].r)
{
res++;
k = nnum[j].r; //每次更新成n数组的右边界
}
else //右边界一旦超过,直接扔掉后面的部分结束质询
{
break;
}
}
}
cout << res << endl;
}
delete[] nnum;
delete[] mnum;
}
}
最优装载问题
贪婪策略:
将重量从小到大排序,优先装入重量小的物品。
题目描述1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21Description
有一批集装箱要装上一艘载重量为C的轮船。其中集装箱i的重量为wi。最优装载问题要求确定在装载体积不受限制的情况下,将尽可能多的集装箱装上轮船。
Input
输入的第一个为测试样例的个数T( T <= 100 ),接下来有T个测试样例。每个测试样例的第一行是一个整数n( n <= 1000 )和一个非负数C( C <= 10000 ),分别表示集装箱的个数以及轮船的载重量。接下来有n行,每行一个非负数,表示每个集装箱的重量。
Output
输出最多装集装箱的个数和最终的承重量。
Sample Input
1
5 100
20
50
120
99
30
代码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
using namespace std;
void Loading(int x[], int w[], int c, int n)
// c为轮船承重量,n为货品的个数,w为货品重量数组,x为记录对应位置是否装上的数组
{
sort(w, w+n);
for (int i = 0; i< n; i++)
{
if (w[i] <= c)
{
x[i] = 1;
c -= w[i];
}
}
}
int main()
{
int n,c;
cin >> n >> c;
int *w = new int[n];
int *x = new int[n];
for (int i = 0; i < n; i++)
{
cin >> w[i];
x[i] = 0;
}
Loading(x, w, c, n);
int sum = 0;
cout << "最优解: ";
for (int i = 0; i < n; i++)
{
cout << x[i] << " ";
if (x[i])
{
sum += w[i];
}
}
cout << endl;
cout << "装载重量为: " << sum << endl;
system("pause");
}
背包问题
贪婪策略:
计算物品性价比,按性价比从大到小排序,优先装入性价比大的。
题目描述1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31临近开学了,大家都忙着收拾行李准备返校,但 I_Love_C 却不为此担心! 因为他的心思全在暑假作业上:目前为止还未开动。
暑假作业是很多张试卷,我们这些从试卷里爬出来的人都知道,卷子上的题目有选择题、填空题、简答题、证明题等。而做选择题的好处就在于工作量很少,但又因为选择题题目都普遍很长。如果有 55 张试卷,其中 44 张是选择题,最后一张是填空题,很明显做最后一张所花的时间要比前 44 张长很多。但如果你只做了选择题,虽然工作量很少,但表面上看起来也已经做了 4/5的作业了。
I_Love_C决定就用这样的方法来蒙混过关,他统计出了做完每一张试卷所需的时间以及它做完后能得到的价值(按上面的原理,选择题越多价值当然就越高咯)。
现在就请你帮他安排一下,用他仅剩的一点时间来做最有价值的作业。
输入格式
测试数据包括多组。每组测试数据以两个整数 M,N(1\leq M\leq 20, 1\leq N\leq 10000)M,N(1≤M≤20,1≤N≤10000) 开头,分别表示试卷的数目和 I_Love_C 剩下的时间。接下来有 MM 行,每行包括两个整数 T,V(1\leq T\leq N,0<V<10000)T,V(1≤T≤N,0<V<10000),分别表示做完这张试卷所需的时间以及做完后能得到的价值,输入以 0\:000 结束。
输出格式
对应每组测试数据输出 I_Love_C 能获得的最大价值。保留小数点 22 位
提示
float 的精度可能不够,你应该使用 double 类型。
样例输入
4 20
4 10
5 22
10 3
1 2
0 0
样例输出
37.00
代码如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
using namespace std;
typedef struct work
{
double t;
double v;
double val;
}work;
bool cmp(work a, work b)
{
return a.val > b.val;
}
int main()
{
while (true)
{
int M, N;
cin >> M >> N;
if ((M == 0) && (N == 0))
{
break;
}
work* arr = new work[M];
for (int i = 0; i < M; i++)
{
cin >> arr[i].t >> arr[i].v;
arr[i].val = arr[i].v / arr[i].t;
}
sort(arr, arr + M, cmp);
double res = 0;
double time = (double)N;
for (int i = 0; i < M; i++)
{
if (time >= arr[i].t)
{
res += arr[i].v;
time -= arr[i].t;
}
else
{
res += (time*arr[i].val);
break;
}
}
cout << setiosflags(ios::fixed) << setprecision(2) << res << endl;
delete [] arr;
}
}
最小生成树
书上的输入方式
其实和灌溉原理一致,只是输入略有不同,没有影响,这里比灌溉增加了连线的顺序方法(不过没有什么特别的,多一个输出而已)
输入方式1
2
3
4
5
6
7
8
9
10
116 10
1 2 6
1 4 5
1 3 1
2 3 5
5 2 3
3 4 5
3 5 6
6 3 4
4 6 2
5 6 6
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
using namespace std;
int f[105];
typedef struct node
{
int l;
int r;
int w;
}node;
bool cmp(node a, node b)
{
return a.w < b.w;
}
int find(int num)
{
if (f[num]==num)
{
return num;
}
else
{
f[num] = find(f[num]);
return f[num];
}
}
int main()
{
int n, m; //n为顶点个数,m为边的数量
cin >> n >> m;
node arr[10005];
int a, b, c;
for (int i = 0; i < m; i++)
{
cin >> a >> b >> c; //防止输入的左端点大于右端点
arr[i].l = min(a, b);
arr[i].r = max(a, b);
arr[i].w = c;
}
for (int i = 1; i <= n; i++)
{
f[i] = i;
}
sort(arr, arr + m, cmp);
int res = 0;
for (int i = 0; i < m; i++)
{
int left = find(arr[i].l);
int right = find(arr[i].r);
if (left != right)
{
res += arr[i].w;
f[left] = right;
cout << arr[i].l << " " << arr[i].r << endl;
}
}
cout << "最小值为: " << res << endl;
system("pause");
}
灌溉
题目描述1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16到了旱季农业生产的灌溉就成了一个大问题。为了保证灌溉的顺利,某县政府决定投资为各个村之间建立灌溉管道。
输入第1行包括一个整数N,表示某县的村庄的数量。(3≤N≤100),第2行-结尾为一个N×N的矩阵,表示每个村庄之间的距离。虽然在理论上,他们是N行,每行由N个用空格分隔的数组成,实际上,他们限制在80个字符,因此,某些行会紧接着另一些行。当然,对角线将会是0,因为不会有线路从第i个村到它本身(任何两个村之间的距离都不大于100000)。
输出只有一个,为修建灌溉管道将所有村庄相连在一个灌溉系统里所需的最小管道长度。
样例输入
4
0 4 9 21
4 0 8 17
9 8 0 16
21 17 16 0
样例输出
28
因为感觉Kruskal算法比较好实现,也比较好懂,所以就用这个算法写了
实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
using namespace std;
static int tmp[101][101];
typedef struct node
{
int l; //边的左端点
int r; //边的右端点
int w; //边的权值
}node;
bool cmp(node a, node b)
{
return a.w < b.w;
}
int findf(int x,int f[]) {
return f[x] == x ? x : f[x] = findf(f[x],f);
}
int main()
{
int n;
cin >> n;
int *f = new int[n+1]; //每个顶点的祖先
node c[10001];
for (int i = 1; i <= n; i++) //初始化每个顶点的祖先,最开始都是本身
{
f[i] = i;
}
for (int i = 1; i <= n; i++) //将矩阵记录下来
{
for (int j = 1; j <= n; j++)
{
cin >> tmp[i][j];
}
}
int k = 0;
for (int i = 1; i <= n; i++) //将边的左右端点,权值赋给node
{
for (int j = i + 1; j <= n; j++)
{
c[k].l = i;
c[k].r = j;
c[k].w = tmp[i][j];
k++;
}
}
sort(c, c + k, cmp); //将边的权值从小到大排序
int resmin = 0;
for (int i = 0; i < k; i++) //遍历这些边,进行顶点的连接
{
int left = findf(c[i].l, f); //找左端点的祖先
int right = findf(c[i].r, f); //找右端点的祖先
if (left != right) //祖先不等,说明没有连接或构成回路
{
resmin += c[i].w;
f[left] = right;
}
}
cout << resmin << endl;
}

