
前言
本篇文章《Webshell Detection Based on Random Forest–Gradient Boosting Decision Tree Algorithm》是和前一篇文章《Detecting Webshell Based on Random Forest with FastText》同一学校所作,研究问题依旧是检测webshell,两篇文章同样是利用了随机森林算法,前一篇结合的是fastText,而本篇文章结合的是梯度提升迭代决策树算法。
研究方法
在前一篇文章中,对于features的提取分为两大步:
- 分析提取文件的静态特征
- 利用PHP-VLD获取文件的Opcode,利用fastText训练文本分类器模型
静态特征
而本篇文章中所用和其相似,但有所提升,作者在前一篇文章的基础上增加了如下文件的静态特征:
1.数据压缩比
由于base64方式压缩的webshell通常具有更均衡的特定字符分布,并且往往具有更高的数据压缩比,因此使用数据压缩比检测webshell,有一定的成效。
2.eval函数的使用
一句话木马的重要特性即eval,一般的一句话木马格式如下:1
@eval ($_post[xxxxx])
因此一个文件的eval的数量是模型训练的一个重要feature。
如此之外,之前的文章利用PHP-VLD提取文件Opcode,再使用fastText训练文本分类器,而本篇文章与之不同,作者将获得的Opcode,使用Scikit-learn从中提取2种特征:TF-IDF向量和Hash向量。
TF-IDF Vector
TF即Term frequency,词频计算公式如下: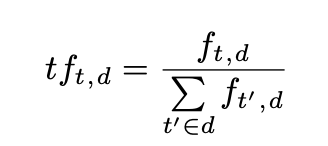
其用来评估一个词语在文本中出现的频率。
IDF即inverse document frequency,逆文本频率指数如下: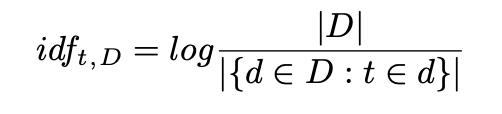
其用于评估该词语在所有文本中是否罕见。
故此TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
其计算方法如下: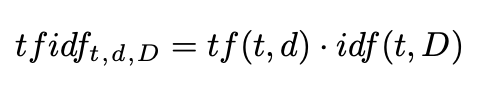
Hash Vector
hash散列可以将任意长度的数据转换为固定长度的数据,同时这种这种转换通常是一对一的,我们很难找到同样的hash对应不同的数据。因此可以利用hash作为某个特征向量的索引,因此无需创建大型字典,而这个恰好是TF-IDF所缺乏的。
例如:特征 i 会被hash到索引位置j:1
h(i) = j
特征 i 的词频表示为φ(i),那么公式如下: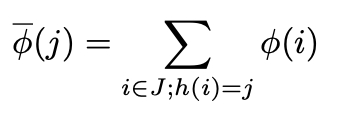
在提取特征结束后,作者尝试在仅适用6个静态特征和GBDT算法进行检测,成功率已达96.9%。
对于GBDT算法,其核心是:每棵树学的是之前所有树结论和的残差,即真实值-预测值。每一轮梯度boosting训练都会减少上一轮训练的残差,即在梯度方向上训练一个新的模型来降低上一轮训练的残差。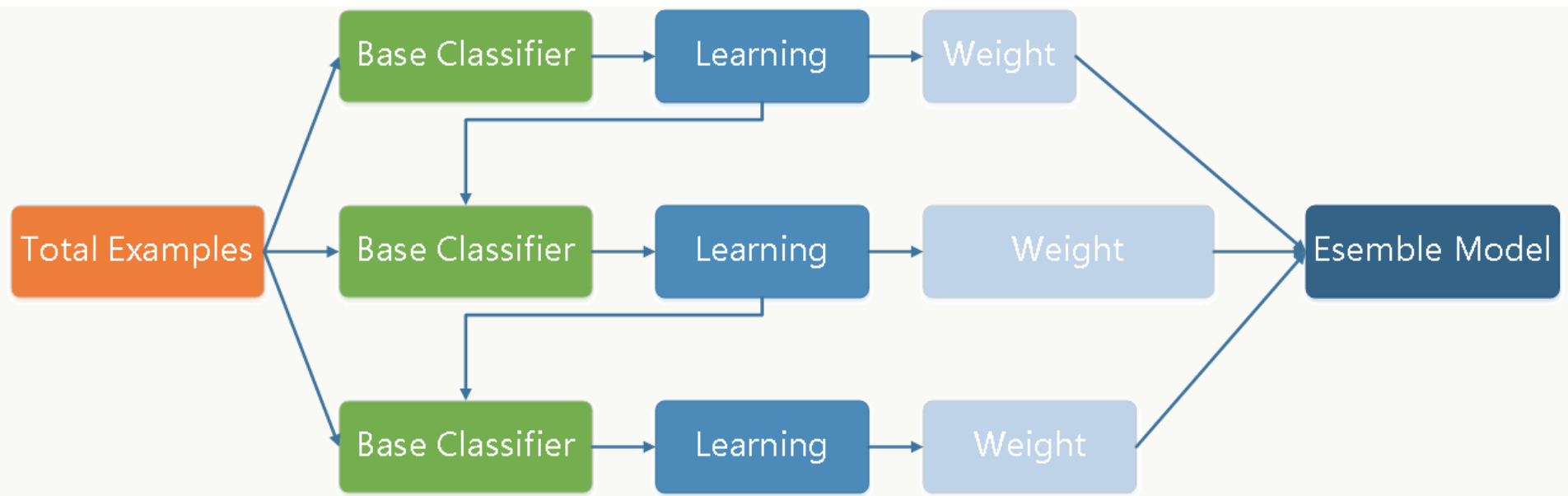
其优点在于可以有效减少feature,降低过拟合现象,并且具有更高的鲁棒性,不太可能受到训练集规模的影响。
这也是作者将其与随机森林算法结合使用的一个原因。同时为了进一步提高效率,作者加入了PHP Opcode的特征提取,和随机森林算法: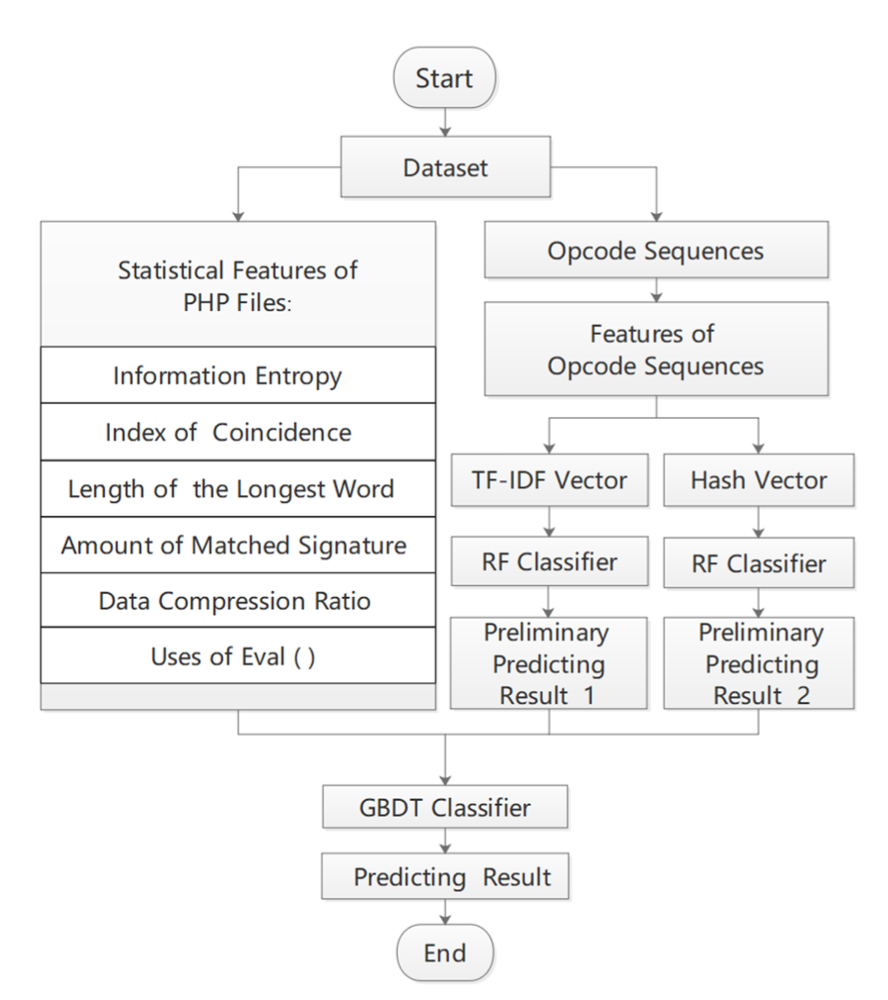
在结合前6个静态特征后,作者使用随机森林获取TF-IDF矩阵和hash矩阵的预测结果,最后结合8个feature对GBDT进行训练。
数据实验
作者从Github收集了2232个webshell,2388 CMS样本文件:
但由于有些文件提取特征不成功,或者并非php文件,作者丢弃了大小超过20000的文件,并未使用。
而后作者从如下几个角度评估了RF-GBDT算法的性能:
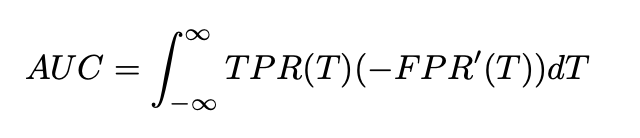
同时作者进行了一些对照实验,结果如下:
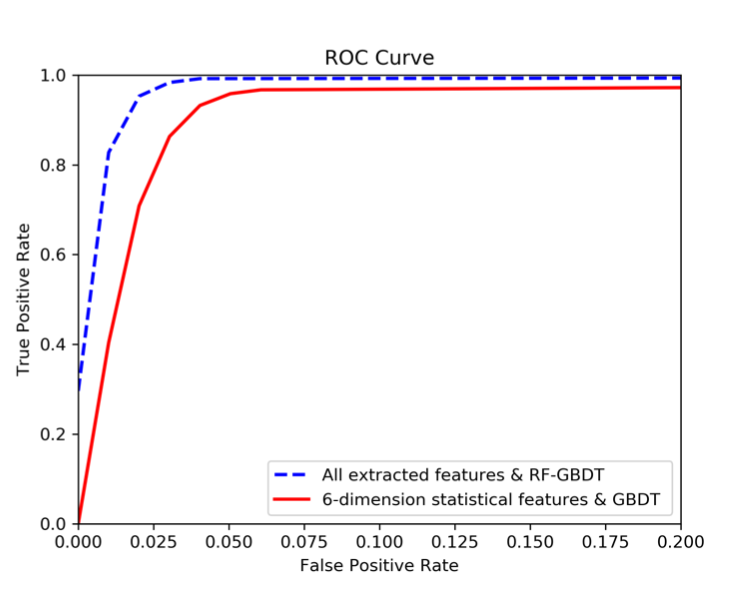
可以看到,如果仅用6个静态features的GBDT在各方面的性能都不如使用8个features的RF-GBDT。除此之外,作者还挑选了一些网上主流的webshell检测工具,结果如下:
这同时也证明了RF-GBDT具有非常好的性能。

