
1
文章首发于 https://xz.aliyun.com/t/2627
前言
最近在看Crypto,记录一下一道题的过程
题干分析
题目名称叫多层,所以我们看到最后的加密形式为1
2
3
4
5
6flag = layer1(flag)
flag = layer2(flag)
flag = layer3(flag)
flag = layer4(flag)
print(flag.decode('ascii'))
那么我们逐层分析
layer1
1 | def layer1(data): |
s的输出为1
ABCDEFGHIJKLMNOPQRSTUVWXYZ
t将s随机打乱重新排列
然后将题目将flag中出现的字频统计出来,打印出来,又将flag中的字母按s-t这个替换表替换
例如:1
2s:ABCDEFGHIJKLMNOPQRSTUVWXYZ
t: NVOJWAXCBQRSMZYUDKILEFTPHG
按这个对应顺序替换(当然t是随机打乱的,这只是个例子),最后再全部转换为ascii编码
我们看一下flag的字频统计:1
Counter({' ': 14, 'O': 6, 'A': 5, 'U': 4, 'I': 4, 'T': 4, 'N': 3, 'D': 3, 'E': 3, 'L': 3, 'H': 3, 'Y': 3, 'R': 3, 'G': 2, 'C': 2, 'F': 2, 'W': 2, '.': 1, '}': 1, 'B': 1, 'V': 1, 'Q': 1, 'P': 1, 'X': 1, 'M': 1, '\n': 1, '{': 1, 'K': 1, 'J': 1, 'S': 1, 'Z': 1})
layer2
第二层很短1
2def layer2(data):
return bytes(b * 17 % 251 for b in data)
将layer1的结果乘17取余251,这也很好反求回来
问题即:我们已知c怎么求b
这里用逆元即可:
17的逆元也很好求,如下:1
2import gmpy2
print gmpy2.invert(17,251)
即可得到192
故此,这一层我们可以轻松取逆
layer3
1 | def layer3(data): |
这一步也很简单,将layer2的结果用同一个key进行异或加密,其中key是最开始随机生成的
乍一看,这里的key无法预测,极大,爆破无解,但是仔细分析,发现只是纸老虎
我们观察到对key的处理1
2key = (key * 0xc8763 + 9487) % 0x10000000000000000
output.append((i ^ key) & 0xff)
这里的1
(i ^ key) & 0xff
是可以使用分配律的,可以拆分为1
(i&0xff)^(key&0xff)
这样一来,我们的key就变成了0~256的一个极小的数,简单爆破即可
并且因为i一定在0x00~0xff这个范围内,所以这一层的求逆也变得很容易1
layer3(c,x)
即可,其中
layer4
来到最后一层1
2
3
4
5
6
7
8
9
10
11
12
13
14def layer4(data):
iv = os.urandom(256)
output = iv
hexencoded = binascii.hexlify(data)
length_target = (len(hexencoded) + 3) // 4
padded = hexencoded.ljust(length_target * 4, b'f')
for i in range(0, len(padded), 4):
r = rsa_encrypt(padded[i:i+4])
block = binascii.unhexlify('%.512x' % r)
output += xor(output[-256:], block)
return base64.b64encode(output)
首先是padded1
2
3
4
5iv = os.urandom(256)
output = iv
hexencoded = binascii.hexlify(data)
length_target = (len(hexencoded) + 3) // 4
padded = hexencoded.ljust(length_target * 4, b'f')
保证data的hex长度是4的倍数,不够用f补齐
然后1
2
3
4for i in range(0, len(padded), 4):
r = rsa_encrypt(padded[i:i+4])
block = binascii.unhexlify('%.512x' % r)
output += xor(output[-256:], block)
将之前加上padding的密文每4个一组,然后进行rsa加密,然后格式化为512长度的无符号16进制,再进行异或加密,这里异或的key是output[-256:],并且一直在变化
大致变化如下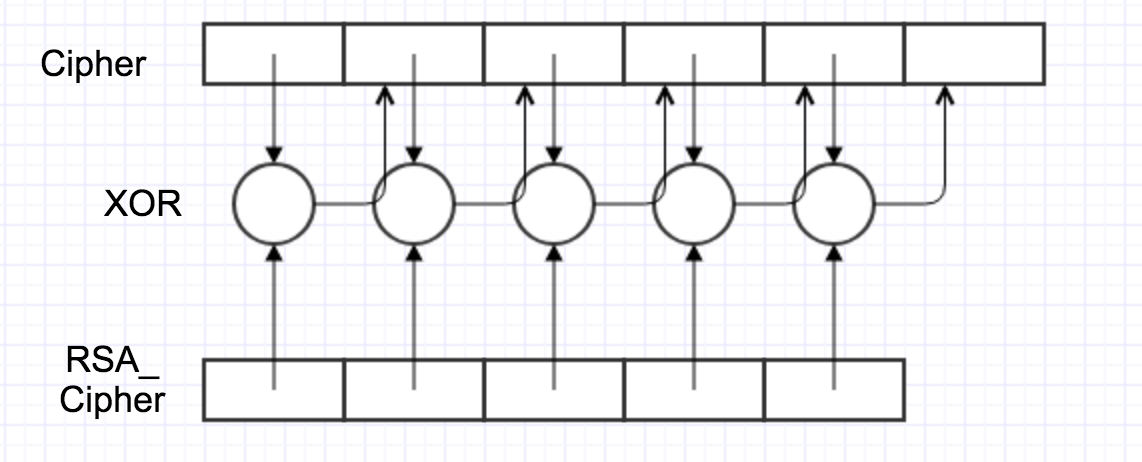
想反解也很容易
用C的后一块异或前一块即可
可以理解为1
c[i-256:i]^c[i:i+256]
即可得到RSA的密文
那么这里的RSA怎么处理呢?
我们看一下RSA的n和e1
2
3
4p = number.getPrime(1024)
q = number.getPrime(1024)
n = p * q
e = number.getPrime(24)
这样随机生成的大n是无法直接破解的,但是我们不难发现
这里RSA加密的消息长度极短,长度只有4,所以这里我们可以用他的n和e遍历加密一遍
生成一个我们的字典,然后根据密文,选择明文即可
例如1
2
3
4
5dec = {}
for i in range(0x10000):
x = b'%.4x' % i
v = number.bytes_to_long(x)
dec[pow(v, e, n)] = x
这样即可成功破解layer4
解题脚本
那么根据上述的思路,我们容易写出如下脚本1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34import base64
from Crypto.Util import number
n=0x80dd2dec6684d43bd8f2115c88717386b2053bdb554a12d52840380af48088b7f1f71c3d3840ef4615af318bbe261d2d2d90616c0d2dcb6414e05c706f2b6d700ed98128048a2b79f57d2c6476add369ec96fb0fed936506d9aee4da5d36aaa97f117b082924c0638923e4367f250cc6cd23918702d98c5359bbb6bad2bef741c65362ad40355fd2edb35248256413d0ee576e7a351f17b9a5a3a7eebbbb2b22f27c342ef6dcaf1396085a105cf5e8b9bbf80e002053347fd9db6e83dc63599b1e1e5a81f7f2e4e2473bc2d14d040c9c6e6f62b9027853c7550a10df49c3a786962c9e9d5b95551a95077d0bd354b88ef31c5625e21edf98f721504f73e1b867
e=0xcf98d5
lines = open('encrypted').readlines()
data = base64.b64decode(lines[3].strip())
def xor(a, b):
res=''
for i in range(len(a)):
res+=chr(ord(a[i])^ord(b[i]))
return res
dec = {}
for i in range(0x10000):
x = b'%.4x' % i
v = number.bytes_to_long(x)
dec[pow(v, e, n)] = x
raw = b''
for i in range(256, len(data), 256):
prev = data[i-256:i]
curr = int(xor(prev, data[i:i+256]).encode('hex'), 16)
raw += dec[curr]
data = raw.decode('hex')
r = number.inverse(17, 251)
for key in range(0,256):
output=''
res=''
for i in data:
key = (key * 0xc8763 + 9487) % 0x10000000000000000
output+=chr((ord(i) ^ key) & 0xff)
for i in output:
res += chr((ord(i)*r)%251)
if res[4:5]=='{' and res[-2:] == '}\n':
print res
break
运行后得到1
SKIT{I VMWPQ ALBCD SBY JMONE BXZL UGZ KIFR HBT WD UGZ PKBMHR HIR CWUGBMU LIWD.}
然后去1
https://quipqiup.com/
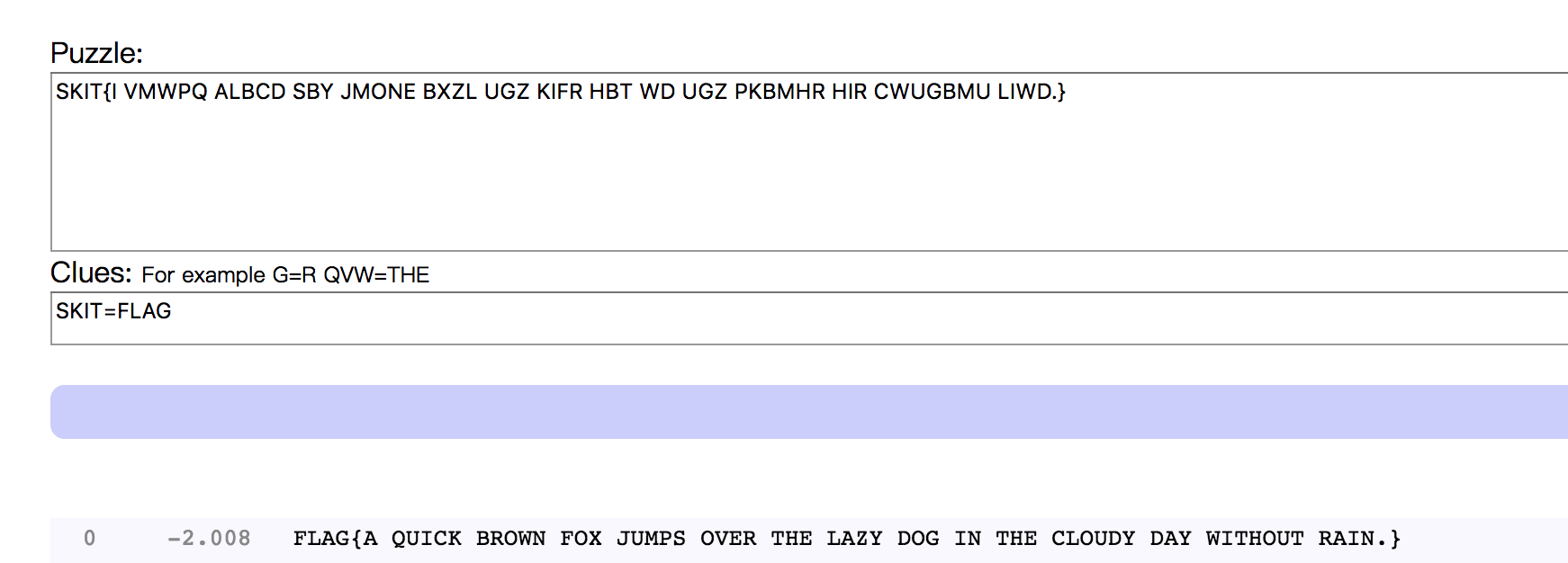
即可得到flag
后记
从这道题里,可以学到一些代换的知识,并且可以得出一个不成熟的推论,就是密码题中如果频繁使用了xor,那么一定有问题XD

